説明可能AI | Explainable AI (XAI)
Gaussian Processes with Local Explanations (GPX)
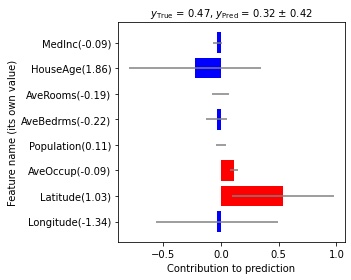
GPX はガウス過程に基づく非線形回帰モデルで、ガウス過程回帰と同等の予測性能を達成しつつ、予測に対する特徴量の貢献度が解釈できるモデルです。 Scikit-learnライクなAPIを提供しています。
GPX is a non-linear regression model based on Gaussian processes (GP), which achieves almost the same predictive accuracy as GP regression and the interpretability of the feature contributios as locally linear regression. Scikit-learn-like API of GPX is available.
Reference
- Yuya Yoshikawa, Tomoharu Iwata, “Gaussian Process Regression With Interpretable Sample-wise Feature Weights,” IEEE Transactions on Neural Networks and Learning Systems, Dec. 2021.
動作認識 | Action Recognition
Meta Video Dataset (MetaVD)
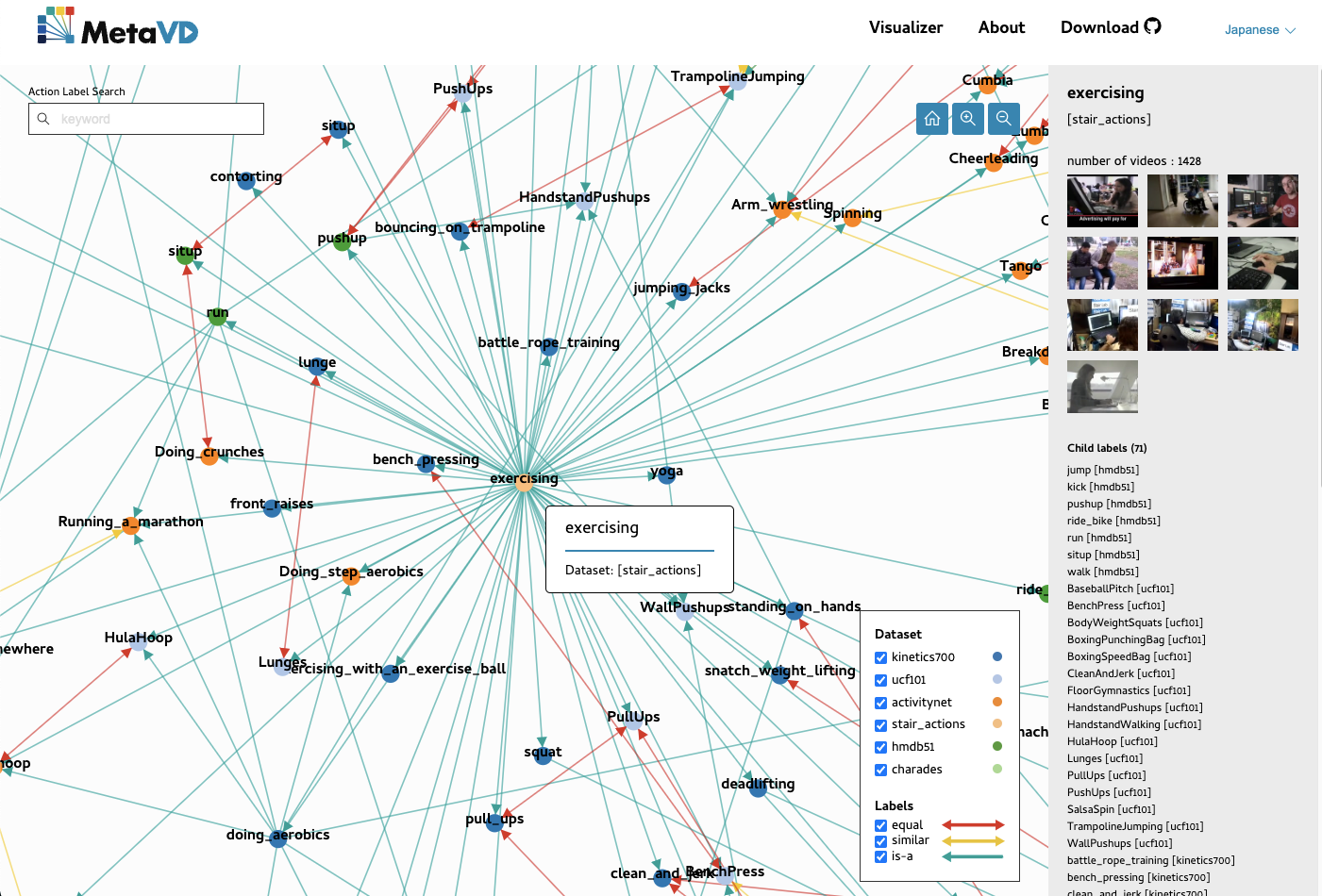
MetaVD は、Kinetics-700やActivityNet等の動作認識データセットの間で、動作クラス間の関係性を人手でアノテーションしたデータセットです。 複数の動作認識データセットを用いた動作認識モデルの学習に活用することを目的としています。 MetaVDで提供されている動作クラス間の関係は、MetaVD Visualizerで調べられます。
MetaVD is is a dataset that provides human annotated relations between action classes across existing human action recognition (HAR) datasets, such as Kinetics-700 and ActivityNet. It can be used to train HAR models with multiple HAR datasets. You can view the relations provided in MetaVD using MetaVD Visualizer.
References
- Yuya Yoshikawa, Yutaro Shigeto, Akikazu Takeuchi, “MetaVD: A Meta Video Dataset for enhancing human action recognition datasets,” Computer Vision and Image Understanding, Volume 212, Sep. 2021.
- Yuya Yoshikawa, Yutaro Shigeto, Masashi Shimbo, Akikazu Takeuchi, “Action class relation detection and classification across multiple video datasets,” Pattern Recognition Letters, Volume 173, Pages 93-100, Sep. 2023. [arXiv version]
STAIR Actions
STAIR Actions は、家庭内で見られる動作100種類を識別する動作認識モデルを学習するために作られたデータセットです。 合計で約10万本の5秒動画クリップを含み、1本の動画クリップに1つの動作ラベルが付けられています。 動画の説明文を生成するモデルを学習するために、STAIR Actionsの約半数に対して動画の説明文を付与した STAIR Actions Captions も公開しています。
STAIR Actions is a dataset which is constructed to train HAR models that can classify videos into 100 home actions. It contains about 100,000 five-second video clips in total, each of which has a single action label. Furthermore, we annotated descriptions for about half of the STAIR Actions videos to train models that generate descriptions from given videos. They are also available in STAIR Actions Captions.

Reference
-
STAIR Actions
- Yuya Yoshikawa, Jiaqing Lin, Akikazu Takeuchi, “STAIR Actions: A Video Dataset of Everyday Home Actions,” arXiv:1804.04326, Apr. 2018.
-
STAIR Actions Captions
- Yutaro Shigeto, Yuya Yoshikawa, Jiaqing Lin, Akikazu Takeuchi, “Video Caption Dataset for Describing Human Actions in Japanese,” Proceedings of The 12th Language Resources and Evaluation Conference (LREC2020), Marseille, France, May 2020.
マルチモーダル学習 | Multimodal Learning
STAIR Captions
STAIR Captions は、STAIR Captions は大規模日本語キャプションデータセットです。 MS-COCO の画像に対して、キャプションを付与しており、全部で820,310件のキャプションで構成されています。 このデータセットを用いることで、画像に対するキャプション生成、検索などの学習を行うことができます。
STAIR Captions is a large-scale dataset containing 820,310 Japanese captions. This dataset can be used for caption generation, multimodal retrieval, and image generation.

Reference
- Yuya Yoshikawa, Yutaro Shigeto, Akikazu Takeuchi, “STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset,” Annual Meeting of the Association for Computational Linguistics (ACL2017 Short paper), Vancouver, Canada, July 2017.